Wordle Solver in Rust
I wanted a low-stakes project to learn Rust beyond toy snippets. Wordle turned out to be the perfect playground: a small, well-defined problem with just enough combinatorics to motivate optimization and concurrency.
Why?
For two reasons, really:
I’ve been playing Wordle off and on, and I got curious about what “optimal” play actually looks like (best average turns, best worst-case turns, etc). I already use exploratory guesses to knock out letters, but I wondered how much better a systematic approach could be.
I wanted to try Rust for real, not just toy snippets. I didn’t have prior experience with Rust so the goal was simply to build something small and see how Rust feels.
I also specifically wanted practice with Rust’s ownership and concurrency modeling as I’d heard it has many ways to prevent bad access patterns. Wordle’s rules are compact, the data is just two text files, and the core loop is pure functions over byte arrays. That makes it easy to iterate, benchmark, and reason about performance.
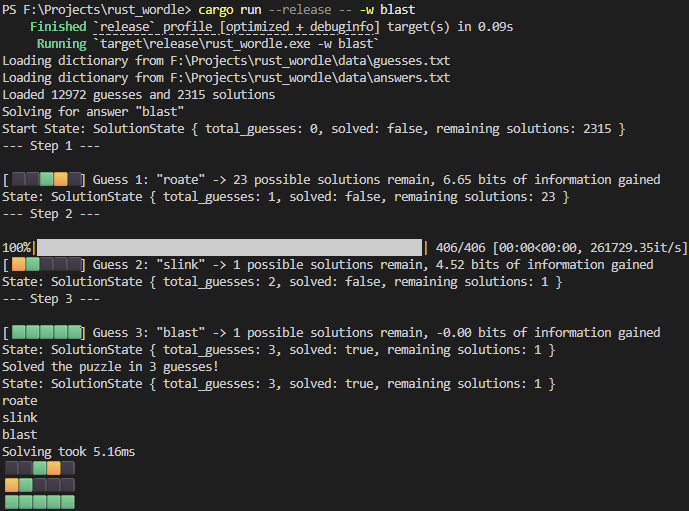
Approach
The greedy strategy I implemented is: pick the guess that, on average, leaves you with the smallest remaining solution set.
Shrinking the solution space makes sense because a Wordle guess doesn’t just test one hypothesis, it produces a full pattern (gray/yellow/green per letter), and that pattern acts like a message that tells you which worlds are still possible.
Lets say you guess “CRANE” and the true answer is “SLATE”, the response pattern will tell you A and E are both correct. Thus, you can assume that any other possible solutions will need to have A and E in those positions. This eliminates a large number of candidates from consideration.
If, for each guess and for each potential solution, you compute the resulting pattern, you can create a new subset of solutions that are consistent with that pattern. By averaging over all possible solutions, you can estimate how much each guess will reduce the candidate set on average. This is assuming of course that all solutions are equally likely.
Then, you pick the guess that minimizes that expected size of the remaining candidate set and repeat until you find the answer. This’ll be if the solution space only contains your answer.
This connects directly to information theory: under a uniform prior, the “uncertainty” in the answer is:
\[H(S) = \log_2 |S|\]After you observe a response pattern, uncertainty drops to..
\[\log_2 |S_r|\]So another (very equivalent) view is to choose the guess that maximizes expected information gain:
\[IG(g) = H(S) - \mathbb{E}_r\big[\log_2 |S_r|\big]\]In other words, we want guesses whose response patterns are as informative as possible on average.
This solver is greedy, it optimizes the next step, not the whole game tree, but it’s a great baseline: simple, fast, and surprisingly strong.
For a great intuition-first explanation of this approach (and the inspiration for my implementation), see this YouTube video by 3Blue1Brown.
A few practical choices helped:
- Preselect a strong opening word (I used
roate), which dramatically reduces the branching early on. - Load
data/answers.txtanddata/guesses.txt(public Wordle lists you can find online) and keep them lowercase and alphabetized.
Parallelization
Part of the fun was building this up in steps.
I started with a straightforward sequential implementation: loop over guesses, score each against the current solution set, compute an expected remaining-candidates value, and take the minimum. Once that was working and easy to reason about, I moved to parallelizing the expensive part.
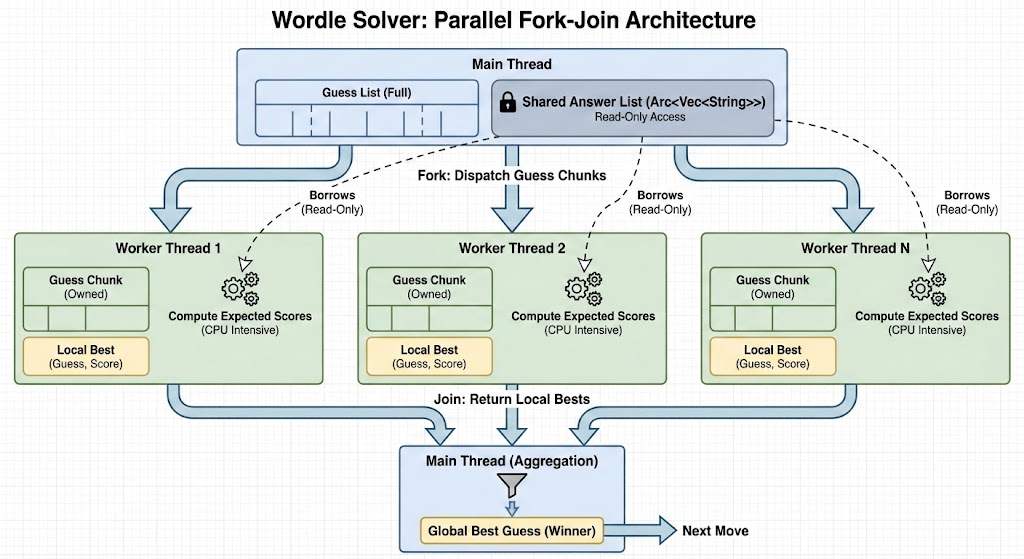
The first big speed win came from parallelizing over guesses. Each worker evaluates a chunk of guesses against the shared solutions list, reports back its best local candidate, and then the main thread reduces across workers to pick the global best. That alone was enough to bring runtimes down into the millisecond range for typical candidate sets.
In total, the steps are:
- Share the current solution set with
Arc<Vec<_>>. - Send chunks of guesses to worker threads in a thread pool.
- Each worker computes expected remaining candidates for its chunk and sends back its best guess and score.
- The main thread collects results and picks the overall best guess.
CLI-wise, I used clap and a single flag:
cargo build --release
./solve --word crane
# or: cargo run --release -- --word crane
Surprises
First, how quickly performance improved with only a little structure: a clean, sequential baseline plus a simple parallel map/reduce over guesses got me as far as I could ask for.
Second, how bad evaluating the first guess was for performance since it has to consider the full solution space. Considering that the first guess does not change for any word, I just hardcoded it to roate.
Challenges
- Minimizing allocations and needless clones takes a bit of care, but choosing good data types lets you avoid most of that.
- The only real lifetime “gotcha” was deciding what to own vs. borrow across threads; cloning once up front and sharing with
Arckept things simple, but it was a bit of a mental shift from C++. - The borrow checker did get in my way at first. Coming from C/C++, I’m used to occasionally leaning on unsafe-ish memory access patterns where I know the usage is ultimately fine. Rust forced me to make those assumptions explicit, decide what owns what, what can be borrowed when, and what needs to be shared. It took a while to internalize the ownership model, but once I did, it was honestly quite simple.
- I added a progress bar so long-running scans feel alive while benchmarking different strategies. This hit performance a little though so I kept the code path that didn’t include it for benchmarking.
Results
On my machine, the release build is extremely fast. I’m happy with the current balance of simplicity and speed, but there’s plenty to try next.
The big next step is to go beyond “best immediate shrink” and do a full deeper exploration: build the result tree induced by each possible guess and evaluate it under different objectives, like:
- minimizing the worst-case number of turns (a minimax-style objective),
- minimizing the average number of turns over the remaining solution distribution.
That means evaluating outcomes at each guess recursively and pruning intelligently when the candidate set gets tiny.
If you want to try it yourself:
- Download public Wordle lists and place
answers.txtandguesses.txtindata/. - Build with
cargo build --release. - Run with
./solve --word <your word>and experiment.
This project did exactly what I hoped: it made Rust’s concurrency model feel approachable and fun, even if the borrow checker gave me some initial headache. The payoff was a small, fast tool I actually enjoy tinkering with. Now, I finish the wordle and take the result back to this solver to see how its solution compares to my own.